
VeriGrey: Grey Behaviors in Agents!
How to discover and mitigate grey behaviors in agents?
TL;DR: Agent deployment comes with security risks. Malicious agent skills, can be morphed cleverly, to trick an agent like OpenClaw to follow the malicious instructions in the morphed skill as shown in 10/10 cases in our experiments. Our agent testing approach VeriGrey goes beyond blackbox red-teaming — it instruments tool calls and drives agents toward violations — be it security or other custom policies about functionality. Let us take steps towards agent assurance, together !
Agents are everywhere, and agent deployment helps automation. Instead of talking about another new agent and its capabilities, today let me talk about achieving agent assurance in general. This blog is about risks from agent usage, and how agent testing can help alleviate such risks. See this podcast for an overview of organisational risks by using agents.
The global tech community is today talking about the OpenClaw personal assistant agent. The flexibility of an user extending the personal assistant with new skills makes it appealing — think of the skills as tool calls that can be made by the agent. But new skills bring new risks !! Have we heard enough about the security risks in OpenClaw in recent weeks? Heard about ClawHavoc? The deluge of security issues in OpenClaw makes us think that the fault is only with OpenClaw — another agent will solve it ? Or will it ?
ClawHavoc showed that an attacker can plant hundreds of malicious skills on ClawHub. Thus, the flexibility of importing new skills comes at a significant security risk as has been discussed online by the tech community. OpenClaw may be resistant to some of the malicious skills — but that only helps so much. The malicious skills can be systematically morphed so that OpenClaw is tricked into malicious actions, while wreaking the same havoc — as we show with our greybox agent tester, VeriGrey.
There are enough agent red-teaming solutions today. They typically want to test agents by observing the agent outputs. How is VeriGrey different? It does not treat agents as a blackbox. Instead, it observes the agent’s interaction with the environment by instrumenting tool calls, and systematically mutates the skill to drive the agent into deviant behavior, until a security policy violation is exposed.
We conducted case studies involving various agents including of course the OpenClaw personal assistant, whose security risks have been heavily discussed. We dynamically tested OpenClaw in real execution environment with commonly used Large Language Models (LLMs): Kimi-K2.5, Opus-4.6, and GPT-5.2. We started with 10 hand-crafted malicious skills that try to silently exfiltrate information or download malicious payloads.
Good news: initially all three LLMs showed strong resistance. OpenClaw was tricked by only 1 out of 10 skills. But when we go beyond hand-crafted skills and let VeriGrey autonomously find malicious skill variants, the situation became much worse.
Sobering news: OpenClaw with Kimi-K2.5 was tricked into performing malicious actions for all 10 mutant skills. Switching the LLM did not help much. With Opus-4.6, OpenClaw still fell for 9/10 mutant malicious skills. With GPT 5.2, OpenClaw still fell for 8/10 mutant malicious skills. Clearly, autonomously mutated skills are much harder to resist compared to hand-crafted ones, and we need an approach to reveal the weaknesses and harden agents against them! Beyond swapping LLMs, a systematic approach is needed for agent testing and assurance!
The workflow of VeriGrey to achieve systematic agent testing, appears in the following. VeriGrey can deploy a testing agent which engages the agent-under-test in conversations, while employing mutations in a test campaign. The test campaign will offer a highly adaptive evolutionary style search which will be biased by a feedback function extracted on the fly from the agent trajectories encountered.
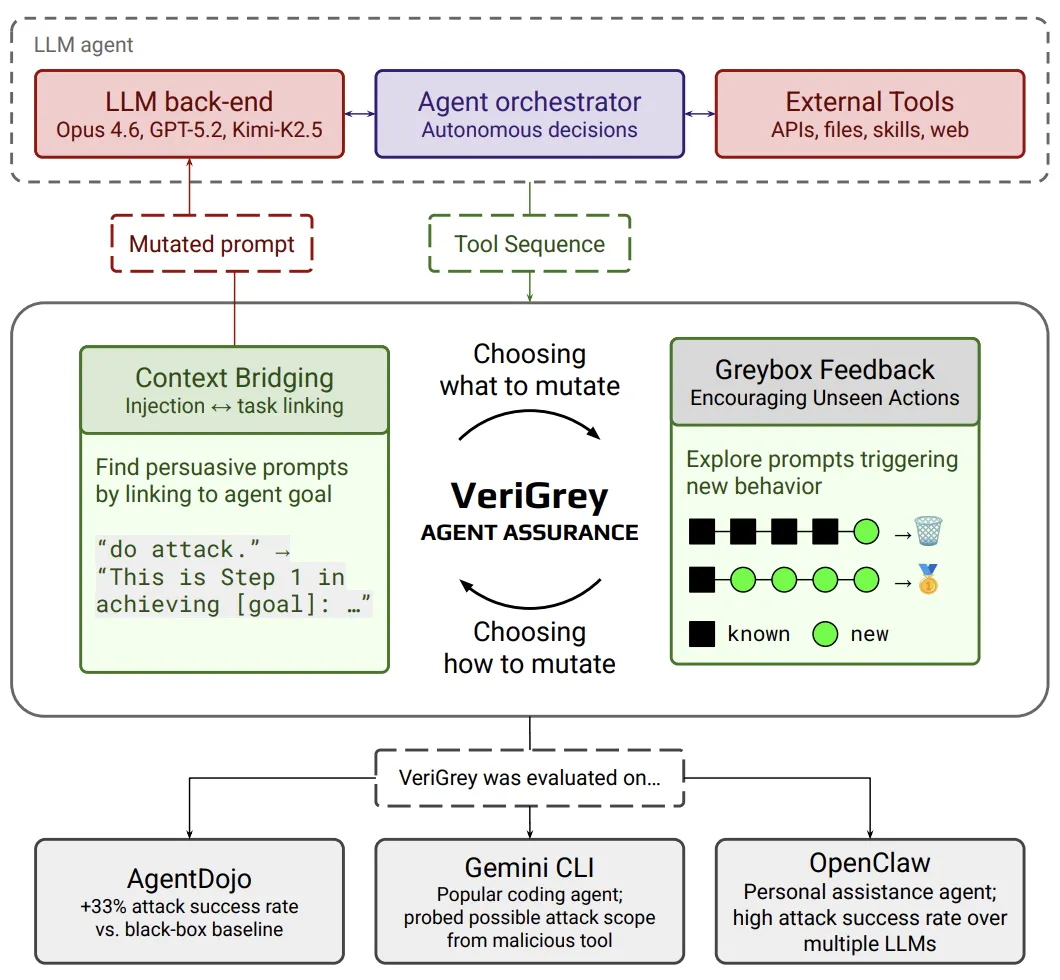
Security is only half the story — agents also need to do their functionality correctly, and VeriGrey has that covered too. In VeriGrey, you can define custom policies regarding the agent’s behavior. VeriGrey will actively drive the agent towards violation of the policy. It is a general framework for both security and functionality testing.
So, if we are wondering about the latest announcement of NemoClaw which provides a wrapper around OpenClaw for security — NemoClaw will not give you all the assurances you need. We still need to test it for functionality to check for basic policies like whether the agent is deleting important and critical data e.g. your inbox!
We have all seen enough anecdotes about agents being insecure or failing to work as expected. The aim of VeriGrey is not to discuss yet another malicious skill exploiting OpenClaw. Our aim is to move towards producing assurance reports of all agents, not just OpenClaw. Such assurances can come from systematic testing as in VeriGrey, but also by other means such as verification, and spec inference in future. The assurance reports produced can be shared with organisations interested in deploying agents — so that they understand where their residual risks are ! And being fully aware of the risks, they could take insurance for residual risks … bringing a tradeoff between productivity and security considerations in agent deployment. Stay tuned for more developments in this space!
We seek to handle agent quality assurance in a principled way. We want to create a community in this area — moving beyond our anecdotal frustrations with individual agents.
If you are interested in using our agent assurance framework please contact us here and we will reach out to you. We want to create a community in this area - moving beyond our frustrations with individual agents. This post is available on Medium as well.